Rivista di informazione del Dipartimento di Ingegneria Industriale
Università di Trento

Negli ultimi anni l’Intelligenza Artificiale è diventata sinonimo di predizione automatica: si forniscono molti dati a una rete neurale, che impara a riprodurre un fenomeno. Ma è davvero questo il modo migliore per modellare un sistema ingegneristico complesso?
Se chiedessimo a un linguista dell’Accademia della Crusca di scrivere un trattato sulle onde gravitazionali, probabilmente egli conosce perfettamente la grammatica e la struttura della lingua — ma ciò non significa che possa automaticamente produrre un contributo scientifico sulla relatività generale. Allo stesso modo, una rete neurale conosce le regolarità statistiche dei dati, ma non conosce la fisica del fenomeno che descrive.
L’Intelligenza Artificiale non sostituisce il modellista, ma diventa uno strumento nelle sue mani.
Nel Dipartimento di Ingegneria Industriale abbiamo recentemente applicato questo approccio allo studio delle emissioni da usura dei freni automobilistici. Il problema è complesso: le emissioni dipendono dall’energia dissipata, dalla decelerazione, dalla storia delle frenate precedenti (bedding), e dall’evoluzione dello stato superficiale del materiale.
Un approccio puramente data-driven potrebbe utilizzare una rete neurale “generica”, con molti strati e migliaia di parametri, lasciandole il compito di scoprire da sola tutte le relazioni.
Ma questo ha tre problemi ben noti:
Se la rete non sa nulla della fisica, deve “comprare” conoscenza con i dati.
L’alternativa è un approccio che potremmo definire model-informed neural network: una rete neurale la cui struttura è progettata dal modellista, sulla base della conoscenza del fenomeno fisico.
Nel caso delle emissioni da freno, il modello è stato costruito separando due componenti fondamentali:
È importante sottolineare che in entrambe le parti l’organizzazione interna della rete non è arbitraria, ma dipende a sua volta da conoscenze specifiche del fenomeno fisico. Il modellista decide quali grandezze sono causalmente rilevanti, quali sono secondarie, e per quale componente del modello esse contano.
Non tutte le variabili hanno lo stesso ruolo: alcune grandezze determinano la componente stazionaria (ad esempio l’energia dissipata); altre influenzano la dinamica e la memoria del sistema; altre ancora possono essere trattate come rumore non modellato.
In questo senso, il modellista esplicita i nessi causali, specifica quali grandezze contano e per cosa contano, e traduce questa conoscenza nella struttura stessa della rete.
Questa operazione equivale a un processo di meta-learning guidato dall’esperto: non è solo la rete che apprende dai dati, ma è il modellista che fornisce alla rete una struttura coerente con la fisica, restringendo lo spazio delle soluzioni possibili prima ancora dell’addestramento.
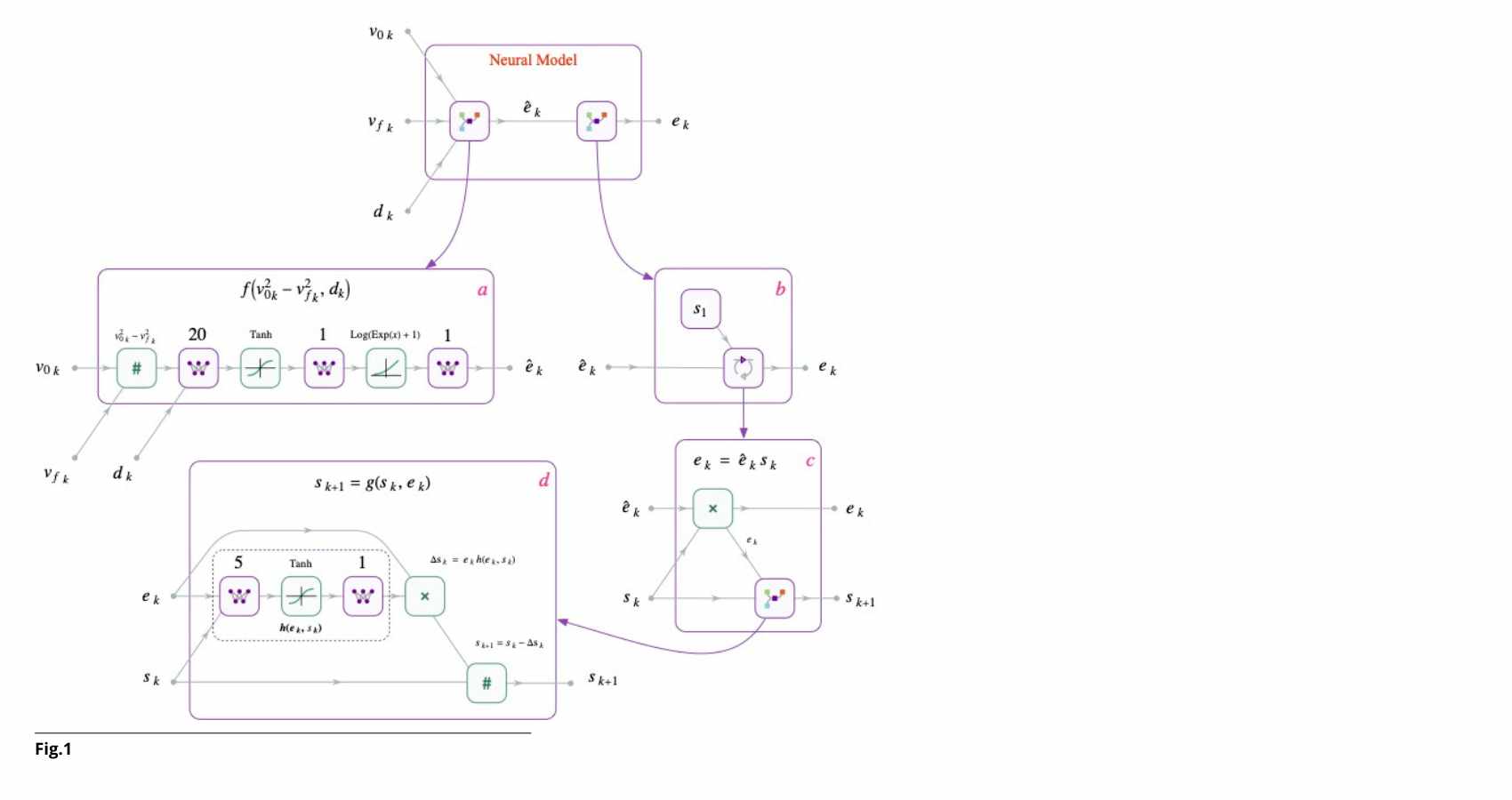
L’architettura risultante non è una “scatola nera” indistinta: un primo modulo calcola la componente di base delle emissioni; un secondo modulo ricorrente aggiorna uno stato interno che modula le emissioni in funzione della storia precedente.
Il risultato è un modello con poco più di cento parametri, ma con una struttura coerente con la fisica del problema.
Box tecnico — Come funziona il modello?1) Ingresso fisicamente significativo. Gli input della rete derivano direttamente dalla fisica: – Energia dissipata - Decelerazione 2) Componente stazionaria . Un primo modulo neurale apprende la funzione che lega energia e decelerazione alle emissioni “di base”. La sua struttura interna riflette ipotesi fisiche sulla dipendenza energetica del fenomeno. 3) Stato interno ricorrente . Un secondo modulo introduce una variabile di stato che evolve a ogni frenata e rappresenta un descrittore macroscopico della condizione superficiale del sistema. Anche qui, la forma dell’aggiornamento dello stato è ispirata alla conoscenza della dinamica tribologica. Emissioni finali = Stato interno × Emissioni di base Questa struttura consente di catturare la memoria fisica del sistema con un numero limitato di parametri e alta interpretabilità. |
Efficienza computazionale: la struttura incorpora vincoli fisici, riducendo parametri e rischio di overfitting.
Flessibilità rispetto alle equazioni rigide: permette di modellare non linearità complesse senza formulare equazioni chiuse per ogni meccanismo.
Integrazione tra teoria e sperimentazione: mescola principi fisici precisi con regole apprese dai dati.
La rete neurale è uno strumento sofisticato. La fisica è la bussola.
È dall’incontro tra le due che nasce una nuova frontiera nella modellazione dei sistemi ingegneristici complessi.
Fig.: Block diagram of the recurrent neural network model, composed of one module (a) that learns the function in (2) and a second module (b) that learns the state dynamics (3). Both modules have physics-informed structures.